

















Boards are asking the same question across every industry: Why aren’t we ten times more efficient?
They use AI tools daily, summarize documents in seconds, and query data without analysts. The productivity feels real and personal. So, when the executive team brings forward another AI initiative, the contradiction is uncomfortable — the tools clearly work, but the organizational return isn’t showing up anywhere measurable.
Part of the reason is structural. In a recent HTEC Today interview, HTEC Chief Strategy Officer Lawrence Whittle put it directly: “It’s not that people are going away from enterprise software — it’s been relegated to plumbing, and all of the value is seen on top of these workflows.” Most enterprises are still measuring the plumbing. The ROI is sitting in the layer above it, uninstrumented and unclaimed.
Most AI programs don’t fail because they produce no results. They fail because nobody agreed on how to measure those results before the first line of code was written. And the narrative has already shifted in a telling way: the early fear of “AI will reduce my headcount” has almost entirely given way to “how do I make my existing team perform like two teams?” That reframe is not cosmetic. It changes the unit of measurement, the metrics that matter, and where you look for value.
ROI in AI engineering is the measurable business value generated from deploying AI systems, relative to the full cost of building, running, and maintaining them.
What Makes AI ROI Structurally Different
The version of this conversation that rarely gets said directly: AI ROI is not a build problem. It is a permanent operations problem that compounds with every user you add.
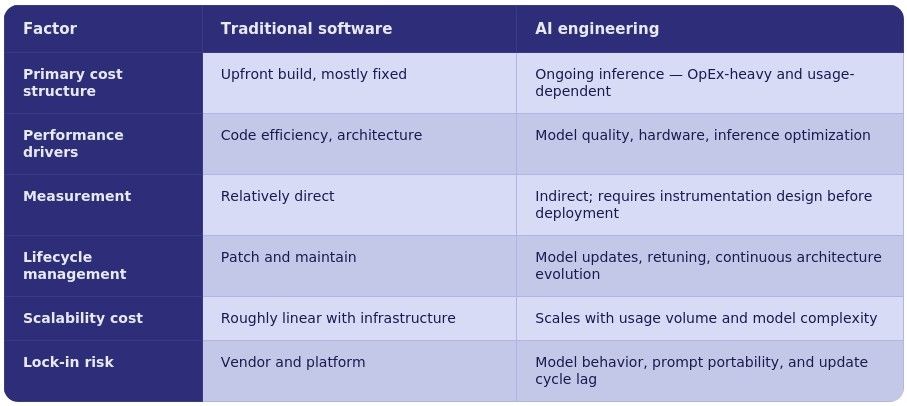
Traditional software cost is front-loaded. With AI engineering, the hard financial question is not “did we build the right thing?” Rather, it is “can we afford to run this at the scale we need, for as long as we need, while the underlying models keep changing underneath us?”
This matters more than it appears. Consider a large-scale consumer application, e.g., one billion users with a single AI interaction per day. The inference bill at that volume dwarfs the original build cost by orders of magnitude. The CapEx of building is a one-time event. The OpEx of running scales permanently with demand, and unlike traditional compute costs, it doesn’t follow predictable infrastructure curves. It follows model complexity, agent reasoning depth, and usage patterns that product teams rarely model accurately in advance.
There is a second cost that almost every enterprise ROI model misses: the weight of the integration and organizational change required to move from a working POC to enterprise production. Getting to a proof of concept is fast, often measured in days. Making that same solution work across a global organization, in compliance with multiple regulatory frameworks, across hundreds of tools and data systems, for hundreds of thousands of users — that is a fundamentally different engineering problem, and the cost of it is systematically underestimated.
Then there is the model update problem, which is specific to AI and has no real parallel in traditional software. The AI chip market has seen over 170 new semiconductor companies emerge in the last two years. Each brings specialized hardware for inference workloads. Each requires its own software stack to run AI models efficiently. Currently, implementing a new model on specialized inference hardware takes four to twelve weeks per update cycle. By the time the integration is complete, a newer model has shipped. This is not a niche infrastructure concern. It is a direct drag on the competitive value of any AI-enabled product, and it belongs in every ROI model as an ongoing cost line.
Why Measuring ROI Breaks Down in Practice
The baseline problem. The practical answer here is counterintuitive: don’t wait for perfect instrumentation before starting. Get started, establish a baseline from real usage, then accelerate from it. The baseline becomes the foundation of your ROI case — but only if you move fast enough to build it before competitors establish theirs. A three-year lead in AI adoption can now be erased in months. The cost of building and iterating has collapsed. Late movers don’t get the grace period they once did.
The competency gap nobody admits. HTEC’s survey of 1,529 C-level executives found that 60% acknowledged needing external partners to close their AI capability gap, while at the same time believing they had sufficient internal talent. That contradiction is precisely where ROI projections break down. The gap between knowing where AI can add value and having the organizational competency to deploy it at scale is real, large, and almost never fully accounted for in business cases. In his interview, Whittle described what he sees across every executive conversation right now — I don’t go to any executive meeting now without them already saying, “I’ve got a hypothesis of where the use cases are — and that hypothesis list is very, very long.” When you look at the competencies that most companies have versus the list, it’s totally misaligned.
The measurement ownership gap. AI ROI spans functions that don’t naturally share data or frameworks. CTOs measure feasibility and architecture quality. CFOs measure cost structure. CIOs measure data sovereignty and compliance exposure. Without a shared framework imposed before deployment, the same initiative produces contradictory ROI narratives depending on who is presenting. Needless to say, contradictory narratives get challenged, delayed, or defunded.
The time-to-value mismatch. AI systems deliver their most significant value after model tuning, workflow integration, and proficiency ramp — not at launch. Budget cycles typically demand a three-month ROI answer. Organizations that force early measurement regularly conclude, incorrectly, that the investment isn’t working, and pull back exactly when the return is about to compound.
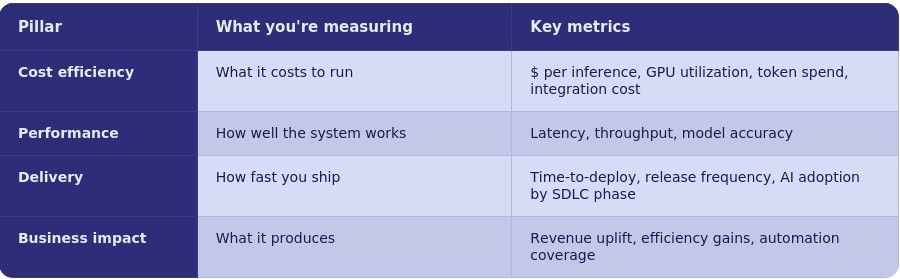
The Four-Pillar Framework
Cost Efficiency — model right-sizing is the most underused lever here. Routing all requests to the largest available model because it produces the best output is the AI equivalent of using a data center to run a spreadsheet. Matching the smallest capable model to each specific task is where 40–60% inference cost reductions are being achieved in production. Factor in the full integration cost, and the true operational cost of an AI deployment is typically three to five times the initial build estimate.
Performance — the metric that rarely appears in ROI models but should: time to model update. Because foundational models improve and are superseded on a cycle of months, the competitive value of any AI product degrades continuously unless the architecture allows rapid model substitution. Model lock-in is not just a vendor risk — it is a financial one. Switching foundational models is not plug-and-play: the same prompt sent to different models produces different outputs, which means prompt logic, output validation, and downstream processes all require rework. The ability to swap models in weeks rather than months is a measurable source of ongoing ROI.
Delivery Efficiency — this is the pillar with the clearest near-term evidence, and the one where the organizational model is visibly changing. The emerging delivery unit is what some practitioners now call the “forward deployed engineer” — a role that combines product management, business consulting, and software engineering, operating in cycles of hours or days rather than months. This role has a productivity profile that traditional velocity metrics understate. The measurement implication: track phase-by-phase, not in aggregate. AI acceleration is not uniform — development and testing phases typically see the highest multipliers; deployment tends to see the least. Aggregating to a single velocity number loses exactly the signal that tells you where to invest next.
Business Impact — the reframe that matters here is from headcount reduction to output multiplication. The organizations seeing the clearest business ROI are not asking “how many fewer people do I need?” They are asking “how much more can the same people produce, and at what quality?” That question requires different metrics: scope per engineer, feature cycle time, defect cost avoided, and customer outcomes per product iteration. It also requires instrumentation before deployment. Business impact claims that can’t be traced to a pre/post baseline don’t survive scrutiny.
How to Calculate It
ROI = (Total Business Value – Total Cost) / Total Cost
Total Cost must include: build, inference at projected scale, infrastructure, integration and services, and model update costs over the solution lifecycle. The most common error is building a cost model around the POC and scaling it linearly. The non-linear costs — model updates, compliance rework, integration maintenance — are where projections break down.
- Capture baseline metrics before the project starts — not estimates, actuals
- Define specific, measurable outcomes upfront — vague targets produce unfalsifiable claims
- Measure at 30, 90, and 180 days post-launch, accounting for proficiency ramp
- Aggregate across all four pillars, subtract total cost, divide, present with assumptions visible
Here’s what it would look like in practice. A 50-person engineering team adopts an AI-integrated development toolchain. Pre-AI baseline: 3.8 deployments per week, 4.2% bug escape rate, 72-hour average from requirements to production code. Post-adoption at 90 days: 4.2 deployments per week, requirements-to-code time down 60%, bug escape rate down to 1.8%. Annual toolchain cost: $480K. Measured value from delivery acceleration, reduced rework, and faster time-to-market: $1.67M. ROI: 247%.
Traditional Software ROI vs. AI Engineering ROI
What Production Deployments Are Showing
The organizations achieving the clearest ROI share one characteristic: they treated measurement as an engineering requirement, not a finance reporting exercise. The numbers from mature deployments cluster consistently — delivery acceleration averaging 1.9x across SDLC phases, with development (2.3x) and testing (2.4x) outperforming deployment; requirements-to-code velocity up 60% in AI-native environments; bug escape rates below 2% with AI-integrated testing pipelines; and the large majority of delivery escalations surfaced and resolved before they become visible to stakeholders.
The organizations at the lower end of these ranges share a different characteristic: they measured after the fact, without baselines, and wondered why the numbers were hard to defend.
FAQ
What is ROI in AI engineering?
The net business value produced by AI systems — cost savings, performance improvements, delivery speed, and business outcomes — relative to the full lifecycle cost of building, running, and maintaining them. It differs from traditional software ROI in three structural ways: inference costs accumulate continuously at scale; moving from POC to enterprise production carries a significant integration cost that compounds with organizational complexity; and model maintenance is ongoing, not periodic, because the models themselves keep improving and being superseded.
How do you calculate AI ROI?
ROI = (Total Business Value – Total Cost) / Total Cost. Total cost must include build, inference at projected scale, infrastructure, integration, and model update costs over the solution lifecycle. Define your measurement design before deployment — credible ROI claims require baselines, and baselines require instrumentation from the start.
What metrics matter most?
All four pillars require coverage: cost per inference and infrastructure utilization (cost efficiency); latency, throughput, and accuracy (performance); deployment frequency and AI adoption by SDLC phase (delivery); revenue impact, efficiency gains, and automation coverage (business impact). A number built on one or two pillars is easy to challenge. A number built on all four is a business case.
How long does it take to see ROI?
Delivery efficiency gains are measurable within the first one to two sprints of full toolchain adoption. Infrastructure and cost efficiency gains become visible within 60–90 days. Business impact metrics require 90–180 days and proper instrumentation. The more strategically urgent timing question is competitive: organizations that delay 2–3 years face a gap that well-resourced competitors can close quickly — the cost of catching up has dropped, but so has the time available to do it.
Why do AI projects fail to deliver ROI?
Five causes appear consistently: no baseline captured before launch; inference and integration costs at scale not modeled during the build phase; architecture that can’t swap models quickly as better ones emerge; the competency gap between internal talent and deployment requirements underestimated; and measurement treated as a finance task rather than an engineering one. The common thread is that ROI was considered after the fact rather than designed in from the start.
HTEC builds and scales AI engineering solutions for global enterprises — with measurement, governance, and delivery velocity built in from day one. Get in touch.




