





































According to Synthetic Data Generation Market report published in December 2022 by Allied Market Research, the global synthetic data generation industry was valued at $168.93 million in 2021 and is projected to reach $3.5 billion by 2031.
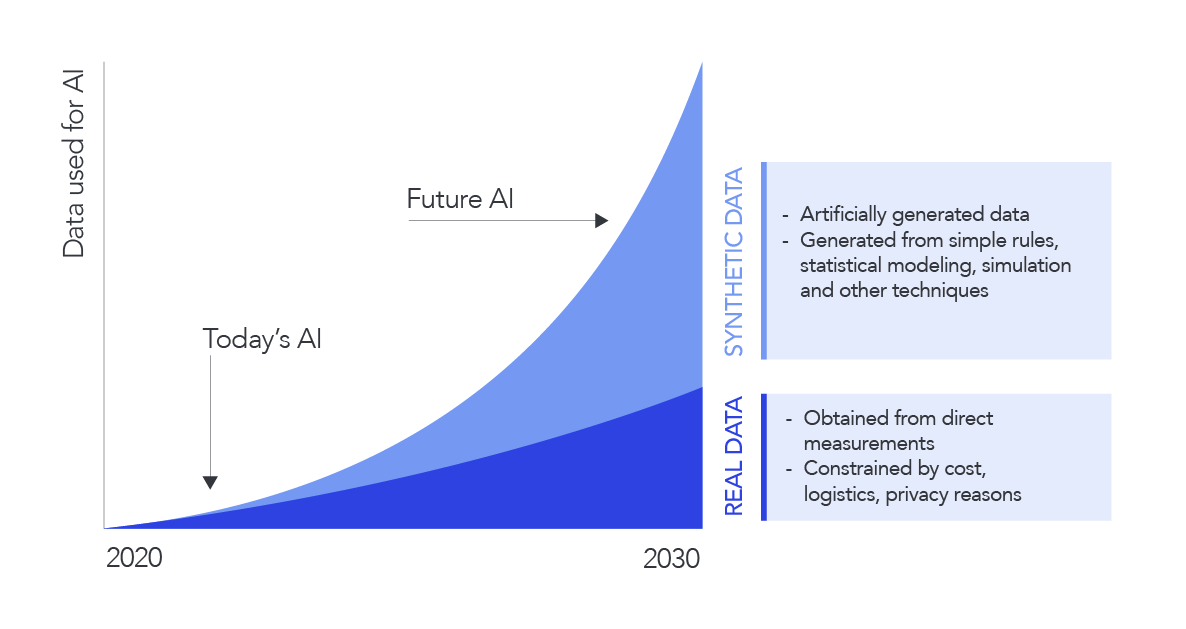
Source: Gartner, “Maverick Research: Forget about Your Real Data – Synthetic Data Is the Future of AI” – 24 June 2021
A surge in demand for AI-driven synthetic data generation in enterprises due to remote work initiatives and rise in adoption of AI technology drive the growth of synthetic data market.
What is synthetic data?
Synthetic data is artificially generated data that mimics the structure and statistical properties of data gathered from real-life events. Depending on data characteristics such as data type and amount, there are numerous ways to generate artificial data, both with and without the use of neural networks.
Why is synthetic data critical?
Privacy
One of the key values synthetic data brings is privacy. While the synthetic data and original data have the same predictive power, synthetic data does not cause privacy concerns that restrict the use of most original data sets.
In the world of data measured in zettabytes there are numerous techniques for data anonymization, yet only with synthetic data there is no 1-1 mapping between original and synthetic dataset and thus no fear of reverse-engineering.
However, be aware that no synthetic data platform can guarantee you 100% privacy – there is a trade-off between data privacy and data utility. Maximizing data utility means we want to preserve the underlying data structure such as patterns and correlations between features. However, the closer you get to the original real-world dataset, the privacy is more jeopardized.
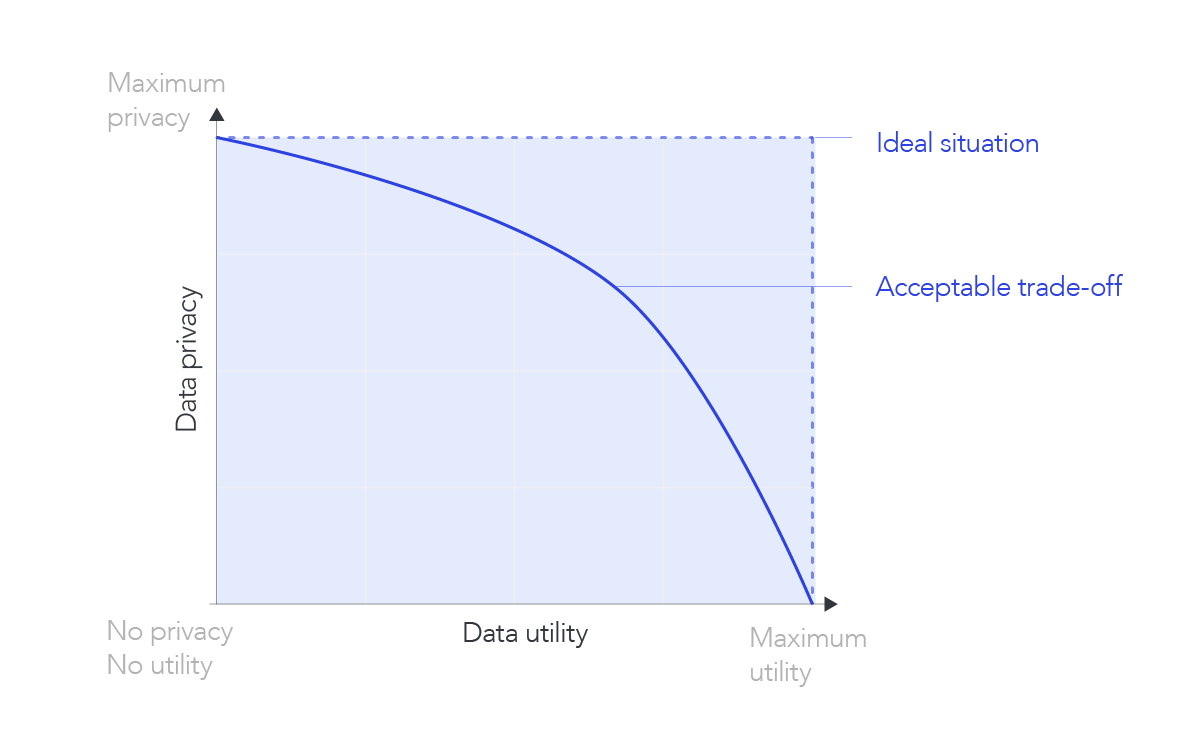
Scalability
Scalability is one of the most important aspects of every business.
With synthetic data, you control the amount and the timing. This not only allows for rapid scale-up of data products but fosters sharing capabilities by avoiding lengthy procedures for data acquisition, both within the companies and with external bodies.
Very often large quantities of data for ML training purposes are either not available or too expensive. Data scientists can overcome this challenge by using synthetic data. The most common use cases are:
- Enrichment of limited real-world datasets – very popular with Amazon, Google and other tech giants which use synthetic data to boost their ML models’ performance.
- Upsampling of rare events – common use case in financial and healthcare industry.
- Creating what-if scenarios — this allows you to train and test models on scenarios that are not represented in the original data. This is a very common use case in fraud detection and defence space.
Quick time-to-market
Collecting and labelling real-world datasets is time consuming and often very expensive. By using synthetic data, data scientists skip these procedures and completely control the process of data generation and manipulation. This decreases the time-to-market of data-driven projects as well as costs.
What about limitations?
Steve Jobs once said, “strengths and weaknesses are the two sides of the same coin”. Here are a few limitations of synthetic data you need to be aware of:
- As previously mentioned, there is no guarantee for 100% privacy. However, identification in ML synthetized data is extremely hard because of the complex data generation models used in synthetization process.
- Unlike other data anonymization techniques, once data is synthetized, it cannot be converted back to the original dataset. This can be a limitation in case you want to hide an individual’s privacy just temporarily but reveal it at the later stage.
- ML-generated synthetic data is big data technology not suitable for small data sets. This makes sense when you know that preserving the statistical properties of real-world data is one of the attributes of ML synthetic data generators.
- If your information is hidden in outliers, synthetic data is not a way to go, as outliers could potentially expose the subjects.
Synthetic data in healthcare
Synthetic data plays important part in the healthcare industry where it’s mainly used for clinical trials and research, but also to increase the volume of data when necessary. Data collection in healthcare is especially challenging because of the strict privacy and security regulations.
To show you a bigger picture of what value Synthetic Data brings, let’s experiment a bit and compare synthetic and original data performance in ML setup.
Problem: Given a set of features, predict the delivery method – vaginal or unplanned C-section.
Original Data: Electronic Health Record (EHR) data containing pregnancies including maternal characteristics and medical information captured prior to, during, and after pregnancies – tabular data with ~100k samples and ~30 features.
Synthetic Data: Synthetic EHR data generated based on original EHR using synthetic data platform.
ML setup: Original EHR data is split into training and test data, training dataset is used as an input into a synthetic data generator. Both original and synthetic training data is trained using XGBoost, while the model evaluation is done on the original test data.

Results: Both models scored 87% of accuracy, while there is a slight difference in recall for unscheduled C-sections. Overall, in this real-case scenario we can see that ML model trained on real-world data and its synthetic version produce comparable results.

The future of synthetic data
Enormous number of devices and complex infrastructures that support data flow enable the exponential growth in data consumption. On the other hand, there is an increase in data privacy rules governing how data should be stored, used and shared. Synthetic data can bridge the gap between extensive amount of real-world data and their application in data driven products by reducing time-to-market of the products, reducing cost and time of data acquisition process and by maintaining privacy of sensitive data.
Data is increasingly impacting system architectures and underlying infrastructures forcing data scientists and engineers to come up with new inspiring and ground-breaking solutions. To learn about how we can help you unlock the real value of data and build next-gen digital solutions, reach out to us our data science team.


