Conduct in-depth user research to reveal market opportunities and incorporate user preferences and behavioral insights to guide digital solution development.
Conduct in-depth user research to reveal market opportunities and incorporate user preferences and behavioral insights to guide digital solution development.
Center of Excellence teams at HTEC stitch together recognized expertise across the firm to accelerate innovation, research, and efficiency in digital solution design, development, and engineering.
E&D drives engineering performance and efficiency for clients at any stage of their digital journey deploying the right expertise at the right time in the right context.
HTEC specialized units and subsidiaries, provide concentrated solutions to help clients address challenges requiring depth of expertise in a specific domain.
Dive into HTEC’s culture, where innovation, collaboration, and growth drive everything we do. Explore our values and what makes HTEC a great place to work.
Accelerating ML through Compilation: Building an ML Compiler that Works
With new models and architecture emerging every day, Deep Learning has been producing a massive impact on the world of technology. For instance, up until recently, LLM (Large Language Models) was not even a familiar term. Now, with ChatGPT pushing large language models to the forefront of media and into daily conversations, everyone wants to run LLM in data centers, CPUs, and even on edge devices.
An increasing number of companies want to bring ML to the edge, which results in more hardware being developed for ML models. Consequently, the need for new compilers arises with the aim to bridge the gap between ML models and hardware accelerators—MLIR dialects, TVM, XLA, PyTorch Glow, cuDNN, etc.
Soumith Chintala, the creator of PyTorch, reflects on this trend by saying that as ML adoption matures, companies will compete on who can compile and optimize their models better.
As the models are becoming bigger, ML compiler teams are faced with a number of new challenges when building compilers that enable the acceleration of ML models. In this article, I will try to demystify the process behind building an ML compiler.
But, before diving into the critical aspects of building a deep learning compiler, let’s first take a look at the most common challenges faced by ML compiler professionals.
Why is building and implementation of ML compiler a challenge?
Compilers translate high-level language to low-level machine code. The same applies to the ML compiler where an ML model has to be translated to machine code for the specific target platform.
Compared to traditional compilers where inputs are C/C++ files and the output is machine code for the target platform, the implementation of ML compilers is more complex and more challenging for several reasons:
1. Models are becoming more complex and require more resources to run on
AI is being used all around. Deep neural networks are applied and used in various domains, from image or video features on mobile phones and autonomous driving applications to conversational agents based on Generative Pre-trained Transformer (GPT) models.
With ML expansions in various domains, models are becoming more complex and require more resources to run on.
Take, for example, a real-world example with VGG16 — a well-known CNN model used for image classification and object detection. This model is used as a backbone (feature-extraction network) for many complex architectures.
For the VGG16 model (without fully connected layers at the end) and with a 126×224 image, the estimated number of multiply-and-accumulate operations (MACs) is 8380M and the estimated number of memory accesses is 8402M.
After reviewing the estimated numbers of memory access/MACs, we can see that running the model efficiently can be a challenge. All the elements—number of computations, number of parameters, and number of memory accesses—are deeply related. A model that works well on mobile needs to carefully balance those factors.
2. The ML ecosystem (or environment) includes a lot of tools and platforms
A variety of ML frameworks (TensorFlow, PyTorch, Caffe2, mxnet, ONNX) and target platforms (from x86, ARM, or RISC-V CPU architectures, nVIDIA and AMD GPUs to different kinds of DSPs or specialized ASICs), make the entire process even more complex.
Every ML framework has a Compiler that takes framework models as input and generates optimized codes for a variety of deep learning hardware as the output. With the constantly increasing need for speed, ML compilers need to be designed to enable easy adaptation, extension, and maintenance to achieve set performance goals in a timely manner.
For instance, to run ML models made in PyTorch, vendors need to provide support.ONNX (a common format for presenting ML models) has around 200 operators (functions). Creating reference implementation of all those functions and enabling the model to run end-to-end can take a significant amount of time. Further optimizations of operators using HW-specific optimizations can be driven by customer needs, but a lot of effort and engineering man-days will be spent on those activities.
In the case of general-purpose architecture, mathematical libraries like Basic Linear Algebra Subprograms (BLAS) already exist. However, execution of optimized versions of mathematical functions can introduce additional performance overhead in preparing the data before and after execution (with the assumption that the format or the layout of ML framework internal representation is different than BLAS).
HTEC has hands-on experience with the implementation and optimizations of mathematical functions for different HW accelerators.
Hardware vendors are trying to provide their own kernel libraries for a narrow range of frameworks. Intel provides OpenVino, a set of libraries that supports plenty of operators from Caffe2, TensorFlow, and ONNX.
Over the last several years, startups have raised billions of dollars to develop new, better AI chips.
Also, big tech companies like Tesla, Google, and Apple have already built their own chips for specific use cases. These specialized types of hardware usually contain multiple processing units or engines. Processing units share very fast memory and high efficiency of multicasting the data between processing units. A single unit can contain one or many different accelerators (DSPs, CPU cores, GPUs, etc.) Splitting the processing operands across units and parallel execution improves hardware capability.
On top of this, some companies are trying to optimize models on the fly and produce highly efficient FPGA code.
How to handle billions of parameters on architecture with limited memory resources, efficiently load and store data, schedule instructions and keep the target accelerator as busy as possible? These are the questions that ML compiler engineers face when building the compiler. Diversity of technical skills (from data science, ML, compiler development to low-level hardware specific optimizations) is the main factor in ML compiler team success.
– Milan Stankić
ML Compiler Engineer, Engineering and Delivery Lead at HTEC Group
Key components of a successful ML compiler development
When creating and bringing new ML models into production, ML engineers must have some level of understanding of ML compilers to successfully run and optimize model execution on different hardware devices.
Led by the experience in working on similar projects, in the following paragraphs, I will try to outline the main components of an ML compiler.
Compiler architecture
The common design of architecture contains frontend and backend, which applies to ML compilers as well. Frontend is responsible for loading the ML model and creating an intermediate representation (IR) of the loaded model. In further compilation steps, compilers can generate several different IRs before the actual code-generation phase.
High-level IR represents the computation and control flow—in most cases, it is represented as DAG (Directed Acyclic Graph) where nodes represent operations and edges represent data dependencies between operations. High-level IR is transformed many times during optimizations and computation graph rewrites have a background in math, linear algebra, or compiler theory.
The low-level IR is designed for hardware-specific optimization and code generation on diverse hardware targets. Therefore, the low-level IR should be fine-grained enough to reflect the hardware characteristics and represent the hardware-specific optimizations. At this point, we are introducing the memory model, latency, scheduling, synchronization, etc.
2. Optimizations
High-level or frontend optimizations are computational graph optimizations performed on the software level. These optimizations remove redundant nodes and replace high-cost nodes with lower-cost nodes. Removing NOP nodes or dead code nodes is done after different optimizations pass.
Algebraic simplifications that rely on commutativity, associativity, and distributivity can help in reducing the number of nodes in a graph. Using the identity elements in binary operations are good candidates to be eliminated from the graph (multiplication by 1, addition with 0, or with 1).
Examples of high-level optimizations:
transposing (combine, eliminate, reshape, sink)
operator ordering (e.g., maxpool before relu)
operator merging (e.g., batchnorm into conv)
operator replacement (FC become matmul and broadcasted add)
quantization specific optimizations (e.g., merge rescaling operations, combining operators with rescale)
dead code elimination (DCE)
common sub-expression elimination (CSE)
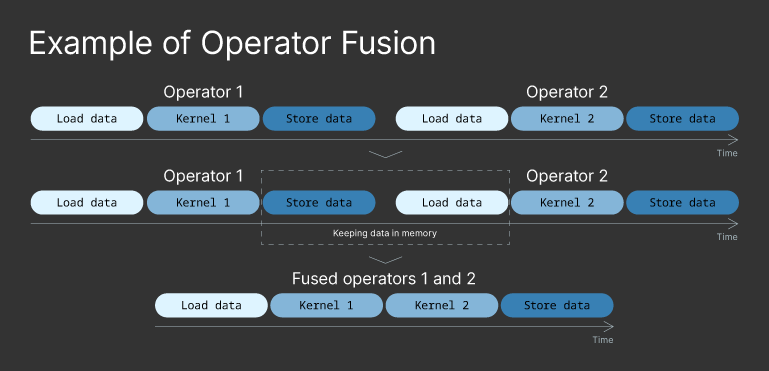
Operator fusion merges different operators (graph nodes) to reduce memory access by not having to save the intermediate results in memory. Sequences of elementwise operations on the same data are good candidates for operator fusion. Finding good candidates for operator fusion is manual work (in most cases).
Low-level optimizations include:
deallocation hoisting/allocation sinking
dead allocation removal
buffer sharing
peephole optimizations
stacking data parallel operations
Differences between the efficiency of generated code, produced by different compilers, are correlated to the actual effort involved in identifying and implementing different graph substitutions and specialized operators and kernels.
As explained in the book Deep Learning Systems by Andreas Rodriguez, fused operators require “that either the primitive libraries, such as oneDNN, MIOpen, and cuDNN or that a backend compiler provides or generates an optimized fused primitive to get the performance benefit.” This means that it is not entirely device-independent.
Regarding the backend optimizations, they are hardware-dependent and change from hardware to hardware.
As Soham Bhure explains in his article Deep Learning Compilers, “hardware-specific optimizations include efficient memory allocation and mapping, better data reuse by the method of loop fusion and sliding window.” By using HW capabilities like SIMD instructions, the utilization of a target can be significantly improved.
3. Code generation
Code generators use optimized low-level IR and produce code for specific targets. Most of the open-source compilers are trying to keep the modular architecture and enable generating efficient code for multiple target platforms (CPU, GPU, custom accelerators, etc.). For example, Google introduced composable and modular code generation in MLIR with a structured and retargetable approach to tensor compiler construction. Using the same IR and producing executables for different platforms is a well-known concept, starting from LLVM.
4. Testing
Testing is a critical aspect here. Compilers need to produce valid and efficient code, and, without good infrastructure, development can be challenging. To introduce new optimization or even change the existing one, a compiler team needs to be sure that regressions are not introduced on different models. Joint work of compiler, DevOps, and Machine Learning teams is mandatory if the company wants to stay in the race for good performances and a broad set of supported models.
Turn on the power of ML
ML is just like any other powerful tool. When used correctly, it can help build. But what is the key enabler?
The path to success hinges on selecting the right people, processes, and technologies, with a clear linkage to business issues and outcomes. HTEC’s team of ML compiler professionals has a wealth of knowledge and experience in successfully overcoming these challenges and enabling the acceleration of ML models. Diversity of technical skills, from data science, compiler design to low-level hardware optimizations and commitment and engagement of HTEC team members enabled customers to run their own models in production.
ML compilers play a crucial role as enablers for further ML model development. They provide a foundation that empowers developers and researchers to create more sophisticated, innovative, and capable machine learning models. A short feedback loop for experimentation, training, and evaluation of models is enabled by an ML compiler.
How to handle billions of parameters on architecture with limited memory resources? How to efficiently load and store data and hide memory latency? How to efficiently schedule instructions and keep the target accelerator as busy as possible?
These are the questions that ML compiler engineers face when building the compiler. Diversity of technical skills (from data science, ML, compiler development to low-level hardware specific optimizations) is the main factor in ML compiler team success.
Explore the links in this blog to learn more about our ML solutions and Data Science team. If you are interested in hearing more about this technology or discussing a use case, let us know at htec.com/contact-us/ or reach out to me on Linkedin.